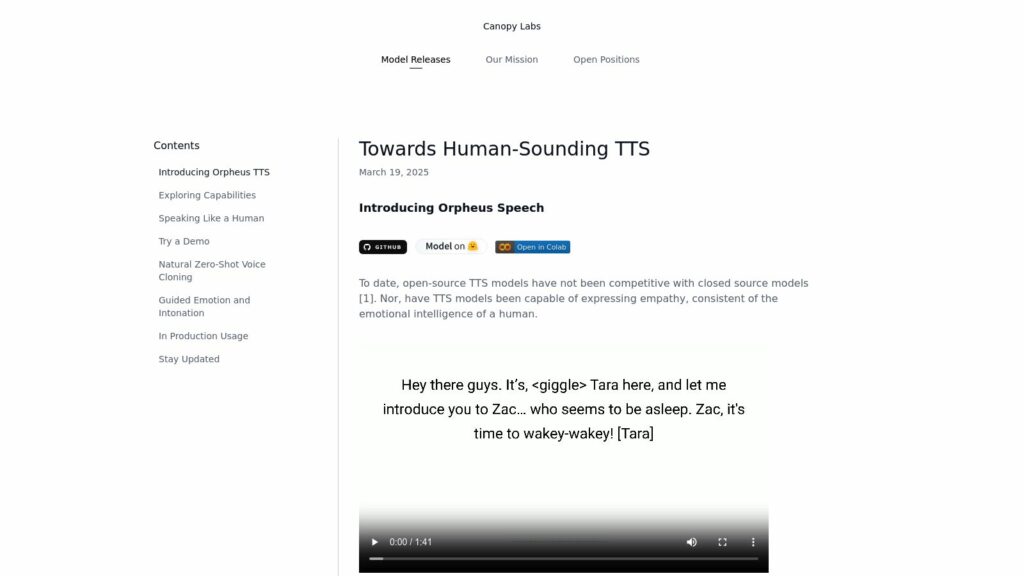
Kokoro TTS: Advanced AI Text-to-Speech Model With 82M Parameters

Kokoro TTS is a cutting-edge, open-source AI text-to-speech model with 82M parameters, offering high-quality, natural voice synthesis. It supports multiple languages, ideal for audiobooks, podcasts, and training videos, and features real-time audio generation, customizable voicepacks, and automatic content segmentation. Users praise its efficiency, lifelike voices, and ease of use, making it suitable for diverse applications like enhancing accessibility and creating educational content.